ChatGPT:
画像認識の世界では、**CNN(畳み込みニューラルネットワーク)が欠かせません。
CNNは、画像を構成する「RGBの3チャンネル(赤・緑・青)」データを効率的に処理する仕組みを持っています。
その発想の源は、なんと人間の脳の「視覚野」**にあります。
人間の視覚を真似た仕組み
私たちの脳の視覚野には「単純型細胞」と「複雑型細胞」があります。
-
単純型細胞:特定の方向や位置の線(エッジ)に反応
-
複雑型細胞:少し位置がずれても同じように反応(位置ずれに強い)
この生物学的な仕組みを人工的に再現したのが、1980年代に福島邦彦によって提案された「ネオコグニトロン」。
このモデルが、のちに深層学習(ディープラーニング)へとつながっていきます。
そして1990年代、**LeCunらが開発した「LeNet」**が登場。
畳み込みとプーリングを組み合わせたネットワークで、手書き文字認識に成功しました。
これが、現在のCNNの原点です。
「叩き込み処理」とは?
日本語では、畳み込み(Convolution)を“叩き込み処理”と表現することもあります。
これは、まさに「人間の視覚野の仕組み」をなぞらえたものです。
視覚野の神経細胞は、網膜上のごく一部にだけ反応する性質を持ちます。
この仕組みを**局所受容野(receptive field)**と呼びます。
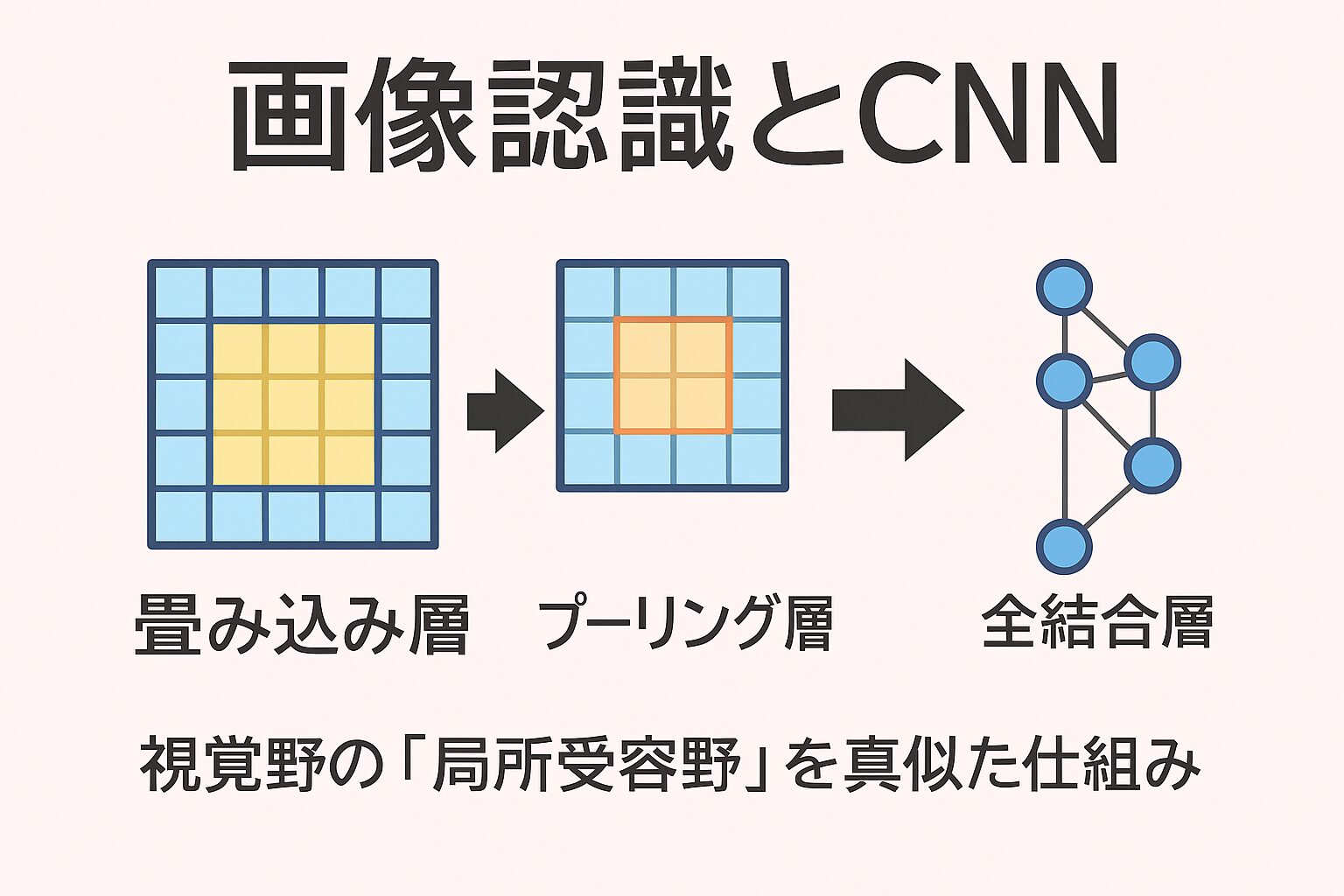
CNNでも同じで、画像全体を一度に見るのではなく、小さな領域ごとに特徴を抽出していきます。
-
畳み込み層 → エッジや模様などの特徴を捉える(単純型細胞に対応)
-
プーリング層 → 位置の変化に強くする(複雑型細胞に対応)
このように、CNNは「人間の見え方」を人工的に再現しているのです。
プーリング処理とGAP(Global Average Pooling)
プーリング層では、画像を一定ルール(最大値・平均値など)で縮小し、
位置の変化やノイズに強い表現を作り出します。
さらに近年では、**全結合層の代わりに「Global Average Pooling(GAP)」**がよく使われています。
GAPは特徴マップ全体の平均値を取るだけなので、
-
パラメータが少なく過学習しにくい
-
入力サイズに柔軟に対応できる
といったメリットがあります。
ResNetやInceptionなどの最新モデルでは、このGAPが標準的な構造になっています。
データを増やす「データ拡張(Data Augmentation)」
画像認識の学習では、あらゆるパターンの画像を集めることは不可能です。
そこで使われるのが、**データ拡張(Data Augmentation)**という手法です。
これは、既存の画像を少し加工して新しい画像を作り出し、
モデルが多様な状況を学べるようにするテクニックです。
代表的な手法には次のようなものがあります。
-
Cutout:画像の一部をマスクして消す
-
Random Erasing:ランダムな領域を削除
-
Mixup:複数の画像を線形補間して混ぜる
-
CutMix:異なる画像を切り貼りして合成する
これらの拡張により、CNNはより頑健で汎用的なモデルに成長します。
CNNの進化:AlexNetからEfficientNetへ
CNNの歴史を一気に変えたのが、2012年のAlexNetです。
このモデルはImageNetコンペで圧倒的な成績を収め、
深層学習ブームの火付け役となりました。
その後も次々と新モデルが登場します。
-
VGG:より深くシンプルな構造で高精度化
-
GoogLeNet:複数の畳み込みを並列に組み合わせる「Inception構造」
-
ResNet:残差接続で“深すぎる問題”を解決
-
MobileNet:軽量でスマホでも動作可能
-
EfficientNet:精度と効率を両立させたスケーリング設計
さらに最近では、AIが自動で最適な構造を探す**NAS(Neural Architecture Search)**の研究も進んでいます。
これにより、設計者の経験に頼らず高性能なネットワークを得ることが可能になりました。
転移学習とファインチューニング
大規模なニューラルネットを一から学習するには、
膨大なデータと計算資源が必要です。
そこで使われるのが**転移学習(Transfer Learning)**です。
例えば、ImageNetで事前に学習されたモデルを使えば、
新しいタスク(例:医療画像や顔認識など)にも少ないデータで高精度な結果を得られます。
応用の仕方は2通りあります。
-
一部の層を固定して最後の分類層だけ学習
-
**全層を再学習(Fine-Tuning)**して新タスクに最適化
後者の「ファインチューニング」は、既存の知識を活かしながら
より専門的な表現を学ばせる強力な方法です。
まとめ
CNNは、人間の視覚の仕組みを模倣した人工知能の“目”。
局所的に特徴を捉え、階層的に意味を組み上げることで、
画像認識や映像解析、医療診断、さらには自動運転など、
幅広い分野で活躍しています。
そして今も、GAP・NAS・転移学習といった新しい技術とともに、
CNNはより軽く、より賢く進化を続けています。
画像データは通常RGBの3チャンネルとして表現され、畳み込みネットワーク(CNN)はそれを効率的に処理する代表的な手法です。CNNのアイデアは、人間の視覚野を真似するところから発展してきました。視覚野には「単純型細胞」と「複雑型細胞」が存在し、前者は特定の方向や位置のエッジに反応し、後者はより位置のずれに頑健に反応します。こうした仕組みを人工的に模倣したものが福島邦彦によって提案された「ネオコグニトロン」であり、その考え方は後に深層学習の発展に大きな影響を与えました。そして1990年代にLeCunらが提案した「LeNet」は、畳み込みとプーリングを組み合わせたネットワークとして手書き文字認識で成功を収め、現在のCNNの礎となっています。
「叩き込み処理」という言葉は、畳み込み(convolution)処理を人間の視覚野の仕組みになぞらえて表現したものと考えられます。
人間の視覚野には「局所受容野(receptive field)」という考え方があります。これは、視覚野の神経細胞が網膜上の限られた領域(小さな範囲)の入力にだけ応答するという仕組みです。例えば、ある細胞は網膜のごく一部の横方向の線分に反応し、別の細胞は縦方向の線分に反応します。
CNNにおける畳み込みフィルタ(カーネル)は、まさにこの「局所受容野」を模倣しており、画像全体を一度に処理するのではなく、小さな領域ごとに特徴を抽出していきます。単純型細胞に対応するのが「エッジや方向を捉える畳み込み層」、複雑型細胞に対応するのが「位置の変化に強いプーリング層」です。
このようにして、叩き込み処理=畳み込み処理は、人間の視覚野の局所受容の仕組みを人工的に再現し、階層的に特徴を組み上げていく基盤となっているのです。
畳み込み処理は、画像からエッジや模様といった特徴を抽出するための処理であり、視覚野の「局所受容野」の仕組みを模倣しています。続くプーリング処理は、画像データを一定のルール(最大値や平均値など)に従って縮小し、位置の変化に対する頑健性を高めます。その後の全結合層では、畳み込みやプーリングによって得られた特徴マップを一列に並べ、分類や回帰といった最終的な予測に結びつけます。
しかし近年のCNNでは、全結合層の代わりに「Global Average Pooling(GAP)」が主流となっています。GAPは特徴マップ全体の平均値を計算して最終的な特徴ベクトルを得るため、パラメータ数が少なく過学習しにくい、また入力画像サイズに柔軟に対応できるといった利点があります。そのため、ResNetやInceptionなどの最新モデルではGAPが多用されています。
画像認識の学習において、あらゆるパターンを想定した画像を現実的に準備することは不可能です。そのため、手元にある限られた画像から新しいバリエーションを生成する「データ拡張(Data Augmentation)」の手法が活用されます。これは、画像を疑似的に変換・加工することで学習モデルに多様な状況を経験させ、汎化性能を高める狙いがあります。
代表的なデータ拡張の手法としては、画像の一部をマスクする Cutout、ランダムに矩形領域を消去する Random Erasing、複数の画像を線形補間して混ぜ合わせる Mixup、異なる画像の一部を切り貼りして合成する CutMix などがあります。これらの手法は、単純な回転や左右反転といった従来の拡張よりも強力に多様性を生み出し、モデルの頑健性向上に寄与しています。
CNNの発展系モデルとしては、2012年に登場し深層学習ブームのきっかけとなった AlexNet、その後によりシンプルで深い構造を採用した VGG、複数の畳み込みを並列に組み合わせる「Inception構造」を導入した GoogLeNet などが知られています。
しかし、単純にネットワークを超深層化すると学習が難しくなり、識別精度がかえって低下する「勾配消失」や「劣化問題」が生じました。この課題を解決するために、残差接続を導入した ResNet や、軽量化を重視しモバイル環境でも動作可能な MobileNet が開発されました。
さらに近年では、ネットワーク構造自体を自動的に探索・最適化する NAS(Neural Architecture Search) が注目を集めています。その成果として、Googleが提案した MnasNet や、スケーリング手法を工夫して高精度かつ効率的な構造を実現した EfficientNet などが誕生しました。これらは、性能と計算資源のバランスを最適化する方向で進化を続けています。
巨大なニューラルネットワークを1から学習させるには、膨大な計算資源と大量のデータが必要となります。しかし実際のタスクでは、そのような環境を整えるのは現実的ではありません。そこで広く用いられているのが 転移学習(Transfer Learning) です。
代表的な例として、画像認識の大規模データセットである ImageNet で事前に学習されたモデルを利用する方法があります。この学習済みモデルはすでに一般的な画像の特徴を捉えているため、新しいタスクに応用することで少ないデータでも高性能なネットワークを得ることができます。
さらに、学習済みモデルの一部だけを固定し、最後の層を新しいタスクに合わせて学習する方法や、ネットワーク全体を対象データで再学習させる方法があります。後者のように、ネットワーク全体の重みを更新する手法を ファインチューニング(Fine-Tuning) と呼びます。これにより、汎用的な特徴を保持しつつ、特定のタスクに適した表現を獲得できます。

コメント