画像認識分野での応用
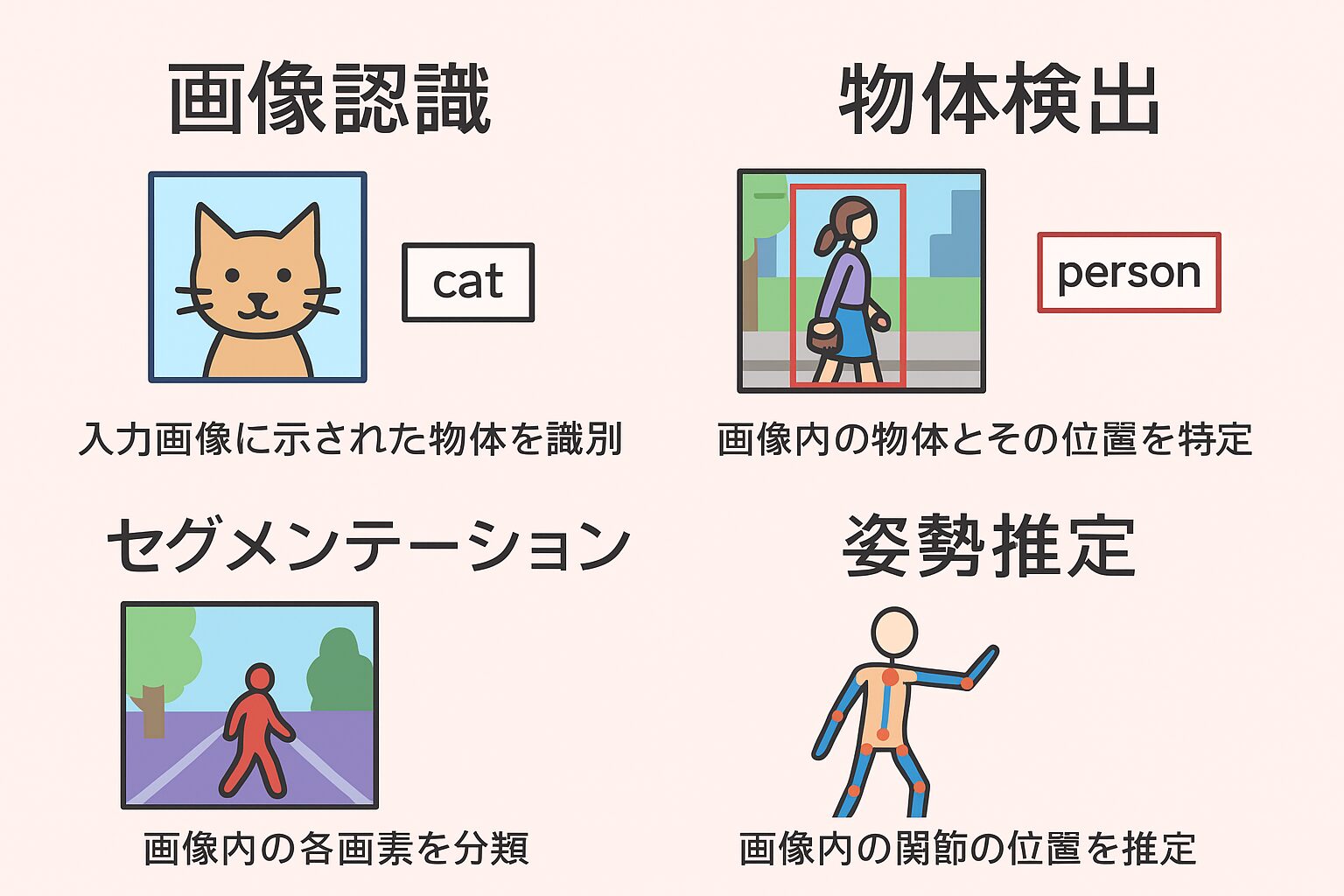
画像認識タスクとは、入力された画像に対して、その画像に映っている代表的な物体クラスの名称を出力するタスクのことを指します。
この分野は深層学習(ディープラーニング)の進展とともに大きく発展してきました。
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)の主な成果
-
2012年:AlexNet
-
深層畳み込みニューラルネットワーク(CNN)を用いて圧倒的な精度で優勝。
-
これを契機に、画像認識分野でディープラーニングが主流となる。
-
-
2014年:GoogLeNet
-
Inception構造を導入し、パラメータ数を抑えつつ高精度を実現。
-
同年、VGGも提案され、単純に層を深くすることで性能向上が可能であることを示した。
-
-
2015年:ResNet
-
残差学習(Residual Learning)のアイデアを導入。
-
非常に深いネットワーク(100層以上)でも学習可能にし、歴史的なブレイクスルーとなった。
-
-
2017年:SENet
-
Squeeze-and-Excitation モジュールを導入し、チャネルごとの重要度を学習。
-
ネットワークが特徴マップの「どのチャネルを重視すべきか」を自動的に学習し、さらに性能を向上させた。
-
つまり、
-
AlexNet → ディープラーニングの時代を切り開く
-
GoogLeNet/VGG → ネットワークの設計思想を発展させる
-
ResNet → 超深層ネットワークの学習を可能にする
-
SENet → 特徴チャネルの選択を最適化する
という流れで進化してきた、と整理できます。
物体検出タスクは入力画像に映る物体クラスの識別とその物体の位置を特定するタスクのこと、物体検出には2段階モデルと1段階モデルが存在する、2段階モデルにはR-CNN,FPN,FastR-CNN,FasterR-CNNがある、1段階モデルにはYOLOやSSDがある
物体検出タスクとは
**物体検出(Object Detection)**は、入力画像に映る物体について
-
クラス(何の物体か)を識別する
-
その位置(バウンディングボックス)を特定する
という2つの処理を同時に行うタスクです。
モデルの分類
物体検出には大きく分けて 2段階モデル と 1段階モデル があります。
🔹 2段階モデル (Two-stage)
-
特徴抽出後に、まず「物体がありそうな領域」を候補として抽出(Region Proposal)し、その後に分類と位置調整を行う。
-
高精度だが計算コストが高い。
-
代表例:
-
R-CNN
-
Fast R-CNN
-
Faster R-CNN
-
FPN (Feature Pyramid Networks)
-
🔹 1段階モデル (One-stage)
-
入力画像から直接、クラスと位置を同時に予測する。
-
高速でリアルタイム処理に向くが、精度は2段階モデルにやや劣ることが多い。
-
代表例:
-
YOLO (You Only Look Once)
-
SSD (Single Shot MultiBox Detector)
-
まとめ
-
2段階モデル → 精度重視、処理は重い
-
1段階モデル → 高速処理、リアルタイム用途に強い
セグメンテーションタスクとは画像の画素ごとに識別を行うタスクのことである、セグメンテーションタスクはセマンティックセグメンテーションとインスタンスセグメンテーションに分けられる、発展駅としてパノプティックセグメンテーションFCN,SegNey,U-Netなどがある
セグメンテーションタスクとは
セグメンテーション(Segmentation)タスクは、
入力画像の 各画素ごとにクラスを割り当てる タスクのことです。
つまり、「どのピクセルがどの物体に属するか」を識別します。
セグメンテーションの種類
-
セマンティックセグメンテーション (Semantic Segmentation)
-
画素ごとにクラスを割り当てるが、同じクラスに属する物体を区別しない。
-
例:画像内に複数の「犬」がいても、全部まとめて「犬」として扱う。
-
-
インスタンスセグメンテーション (Instance Segmentation)
-
画素ごとにクラスを割り当てるだけでなく、同じクラスの個体を区別する。
-
例:画像内の犬Aと犬Bをそれぞれ別の領域として認識する。
-
-
パノプティックセグメンテーション (Panoptic Segmentation)
-
セマンティックセグメンテーションとインスタンスセグメンテーションを統合したもの。
-
すべての画素にラベルを与えつつ、個体の区別も行う。
-
主なモデル
-
FCN (Fully Convolutional Network)
CNNを全結合層の代わりに畳み込み層で構成し、画素単位の予測を可能にした。 -
SegNet
エンコーダ・デコーダ構造を持ち、より精度の高いセマンティックセグメンテーションを実現。 -
U-Net
U字型のネットワーク構造を持ち、医療画像解析などで高精度を発揮。
まとめ
-
セマンティック:クラスごとにまとめる
-
インスタンス:個体ごとに区別する
-
パノプティック:両方を統合

コメント